Kokoro-FastAPI
综合介绍
Kokoro-FastAPI 是一个将 Kokoro-82M 文本转语音(TTS)模型封装起来的工具,让用户能通过一个 FastAPI 接口来使用它。这个项目最大的特点是支持本地化部署,用户数据无需上传到云端,保障了隐私安全。它被打包在 Docker 容器中,简化了安装和运行流程。无论是使用带 NVIDIA 显卡的电脑(GPU加速)还是普通的中央处理器(CPU),都可以运行。Kokoro-FastAPI 提供了与 OpenAI 语音接口兼容的模式,方便熟悉 OpenAI 的开发者快速上手。它还支持多种语言,可以将文本转换成自然流畅的语音,并支持将多个声音模型混合,创造出独特的声音。此外,它还具备流式传输功能,可以一边生成音频一边播放,大大缩短了等待时间。
功能列表
- OpenAI 兼容接口: 提供了与 OpenAI TTS 服务一致的 API 端点 (
/v1/audio/speech),可直接被现有的 OpenAI Python 客户端或其他兼容工具调用。 - 多种运行模式: 支持使用 NVIDIA GPU (通过 PyTorch 和 CUDA) 进行高速处理,也支持在没有独立显卡的普通计算机上通过 CPU (通过 ONNX) 运行。
- 声音混合: 支持将多个不同的声音模型进行组合,可以按特定比例(如 "af_bella(2)+af_sky(1)")混合,创造出新的声音。
- 流式输出: 支持实时音频流输出,能够以极低的延迟(GPU 环境约 300 毫秒)生成并播放音频,适用于实时对话场景。
- 多种音频格式: 支持生成多种主流音频格式,包括
mp3,wav,opus,flac,pcm等。 - 长文本处理: 内置自然边界检测功能,能自动将长文本在句子结束的地方切分处理并拼接,从而支持长篇文章的转换,避免因单次处理内容过长导致的语音质量下降。
- 词语时间戳: 能够生成带有每个单词开始和结束时间信息的数据,方便制作带字幕的视频或音频。
- 音素级操作: 提供将文本转换为音素的接口,也支持直接输入音素来生成音频,为专业用户提供更高的自由度。
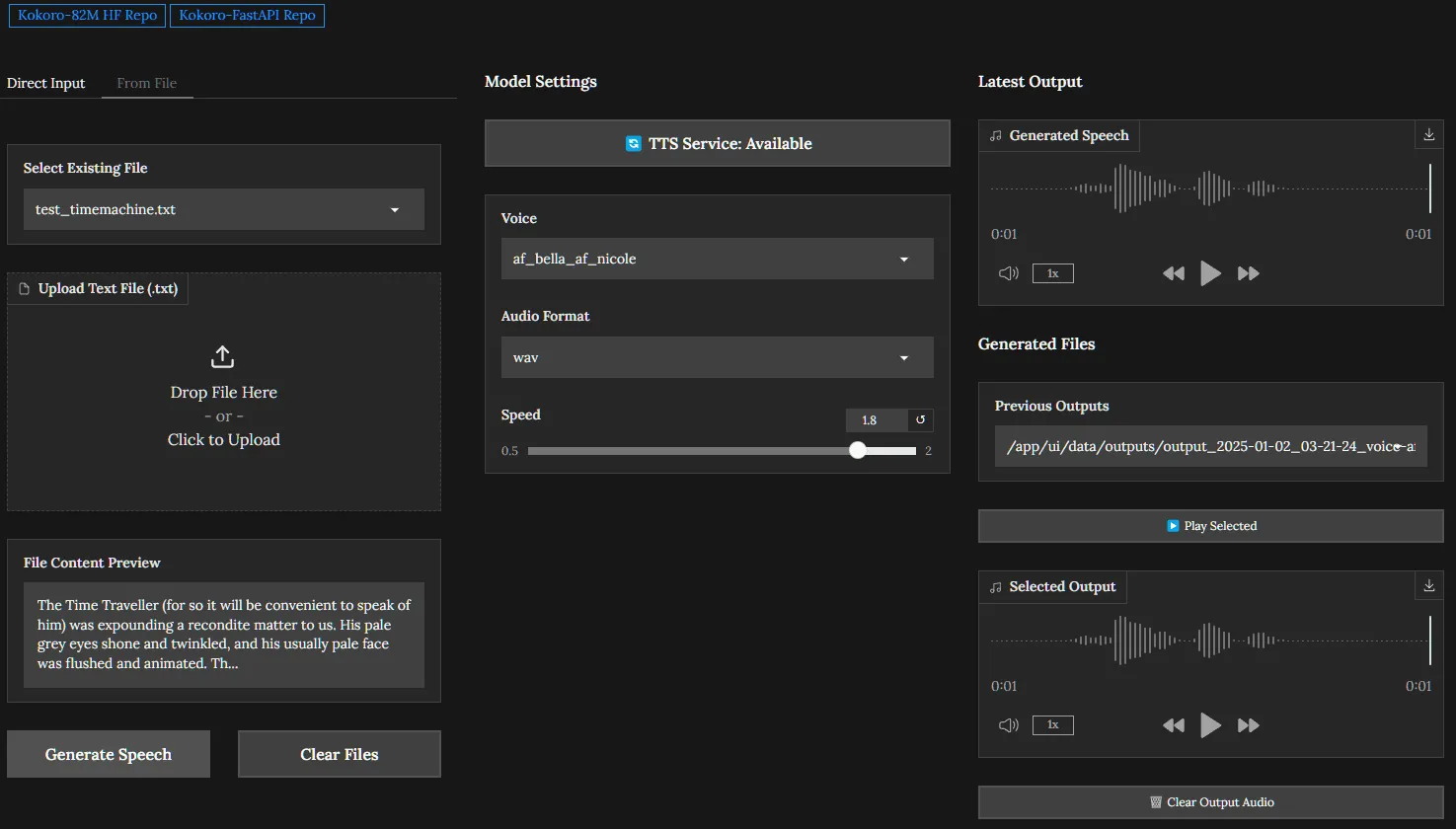
- 集成Web用户界面: 自带一个简单的网页界面,用户可以通过浏览器访问
http://localhost:8880/web直接输入文字、选择声音并生成语音。 - 系统监控: 提供多个调试接口(如
/debug/system),用于监控 CPU、内存和 GPU 等系统资源的使用情况。
使用帮助
Kokoro-FastAPI 主要通过 Docker 进行部署,这种方式简化了环境配置,让用户不必手动处理复杂的依赖关系。以下是详细的安装和使用流程。
环境要求
- 系统: Windows, macOS, 或 Linux
- 依赖: 需要安装 Docker。如果使用 GPU 加速,则需要 NVIDIA 显卡、对应的驱动程序以及 NVIDIA Container Toolkit。
- 硬件:
- CPU 模式: 对硬件要求不高,普通的家用电脑即可运行。
- GPU 模式: 需要支持 CUDA 12.1 或更高版本的 NVIDIA 显卡,性能会比 CPU 模式快 35 到 100 倍。
安装与启动
你可以选择多种方式来启动 Kokoro-FastAPI,最常用的是 Docker Compose。
第一步:克隆项目代码首先,打开终端或命令行工具,使用 git 命令从 GitHub 上下载项目的源代码。
git clone https://github.com/remsky/Kokoro-FastAPI.git
cd Kokoro-FastAPI
第二步:选择运行模式并启动项目提供了针对 CPU 和 GPU 的不同配置。
- 对于 GPU 用户(推荐,速度最快):进入
docker/gpu目录,然后使用 Docker Compose 命令启动服务。cd docker/gpu docker compose up --build第一次启动时,系统会自动下载所需的 TTS 模型文件,并构建 Docker 镜像。整个过程可能需要一些时间,具体取决于你的网络速度和硬件性能。
- 对于 CPU 用户:如果你没有 NVIDIA 显卡,或者不想使用 GPU,请进入
docker/cpu目录,然后运行相同的命令。cd docker/cpu docker compose up --buildCPU 模式的性能会慢一些,但足以满足大部分非实时性的应用需求。
- 对于 Apple Silicon (M1/M2/M3) 用户:目前 GPU 加速依赖于 NVIDIA 的 CUDA 技术,因此苹果芯片的用户请使用
docker/cpu的配置进行安装。
第三步:验证服务是否正常运行当终端日志显示服务成功启动后,你可以通过访问以下地址来验证:
- Web 界面: 在浏览器中打开
http://localhost:8880/web。你应该能看到一个简单的文本输入框,可以在这里直接测试语音合成功能。 - API 文档: 在浏览器中打开
http://localhost:8880/docs。这里是 FastAPI 自动生成的 API 交互文档,你可以在这里查看所有可用的接口并直接进行测试。
如何使用
Kokoro-FastAPI 的核心是它的 API 接口,特别是与 OpenAI 兼容的语音合成接口。
1. 使用 Python 的 openai 库进行调用这是最简单直接的调用方式。你需要先安装 openai 库 (pip install openai)。
from openai import OpenAI
# 初始化客户端,将 base_url 指向你本地运行的 Kokoro-FastAPI 服务
client = OpenAI(
base_url="http://localhost:8880/v1",
api_key="not-needed" # API 密钥在这里不是必需的,随便填一个即可
)
# 创建一个语音合成请求
response = client.audio.speech.create(
model="kokoro", # 模型名称固定为 "kokoro"
input="你好,欢迎使用 Kokoro FastAPI!这是一个由本地驱动的文本转语音工具。",
voice="af_sky+af_bella", # 可以使用单个声音(如 "af_bella"),也可以用 "+" 组合多个声音
response_format="mp3" # 指定输出的音频格式
)
# 将生成的音频流保存到文件
response.stream_to_file("output.mp3")
print("音频文件 output.mp3 已成功生成!")
2. 使用 requests 库进行调用如果你不想安装 openai 库,也可以使用通用的 requests 库直接调用 HTTP 接口。
import requests
# API 的地址
API_URL = "http://localhost:8880/v1/audio/speech"
# 请求体(payload)
payload = {
"model": "kokoro",
"input": "这是一个使用 requests 库发起的测试。",
"voice": "af_bella(2)+af_sky(1)", # 使用括号加数字来指定声音的混合权重
"response_format": "mp3",
"speed": 1.0 # 控制语速
}
# 发送 POST 请求
response = requests.post(API_URL, json=payload)
# 检查请求是否成功
if response.status_code == 200:
# 将返回的二进制内容写入文件
with open("output_requests.mp3", "wb") as f:
f.write(response.content)
print("音频文件 output_requests.mp3 已成功生成!")
else:
print(f"请求失败,状态码: {response.status_code}, 错误信息: {response.text}")
3. 如何进行流式传输流式传输能够让你在音频完全生成之前就开始接收和播放数据,非常适合需要快速响应的场景。
from openai import OpenAI
import pyaudio # 需要安装 pyaudio: pip install pyaudio
client = OpenAI(
base_url="http://localhost:8880/v1",
api_key="not-needed"
)
# 初始化音频播放器
p = pyaudio.PyAudio()
player = p.open(
format=pyaudio.paInt16,
channels=1,
rate=24000, # 采样率需与模型匹配
output=True
)
# 使用 with...as 结构来请求流式响应
with client.audio.speech.with_streaming_response.create(
model="kokoro",
voice="af_bella",
response_format="pcm", # 使用 pcm 格式以便直接播放
input="流式传输可以显著降低首次听到声音的延迟。"
) as response:
# 迭代接收音频数据块并播放
for chunk in response.iter_bytes(chunk_size=1024):
player.write(chunk)
# 关闭播放器和 PyAudio
player.stop_stream()
player.close()
p.terminate()
print("音频播放完毕。")
应用场景
- 内容创作播客、有声书和视频制作者可以使用 Kokoro-FastAPI 生成旁白或配音,无需真人录制,从而节省时间和制作成本。
- 集成智能助手可以作为本地智能助手(如 Home Assistant)的语音输出模块,实现完全在本地网络内的语音交互,保护家庭隐私。
- 辅助工具开发开发者可以将其集成到屏幕阅读器等辅助技术中,为视障用户提供更自然、流畅的语音反馈。
- 游戏开发独立游戏开发者可以用它为游戏中的非玩家角色(NPC)生成对话,无需承担昂贵的专业配音演员费用。
- 各类软件集成可以轻松集成到如 Open WebUI、SillyTavern 等现有开源项目中,为这些应用提供高质量的文本转语音能力。
QA
- 这个项目和直接使用别的 TTS 模型有什么区别?Kokoro-FastAPI 不是一个模型,而是一个让模型变得更容易使用的工具。它将复杂的模型运行、环境配置、长文本处理等问题都封装好了,提供一个标准的、开箱即用的 API 接口。你不需要自己编写代码来处理音频流、声音混合等高级功能,只需要简单调用接口即可。
- 为什么推荐使用 Docker 部署?因为 TTS 模型依赖许多底层的库(如 PyTorch, CUDA, espeak-ng 等),在不同系统上手动配置这些库非常繁琐且容易出错。Docker 将整个应用和它的所有依赖打包到一个隔离的“容器”里,保证了在任何安装了 Docker 的机器上都能以相同的方式、稳定地运行。
- 我可以在没有 NVIDIA 显卡的电脑上使用吗?可以。项目提供了纯 CPU 的运行模式(位于
docker/cpu目录下)。虽然速度会比 GPU 慢,但对于生成短语或非实时生成长音频的场景来说是完全够用的。 - 如何添加或切换不同的声音(voice)?声音模型文件(通常是
.pt文件)存放在api/src/models目录下。你可以将下载的 Kokoro 兼容声音模型文件放入此目录,然后重启服务。在调用 API 时,通过voice参数指定你想使用的声音文件名(不含扩展名)即可。 - 调用 API 时返回错误怎么办?首先,检查 Docker 容器的日志,看是否有详细的错误信息。其次,可以访问项目自带的 API 文档(
http://localhost:8880/docs),直接在网页上测试参数是否正确。如果问题依然存在,可以去项目的 GitHub Issues 页面查看是否有人遇到过类似问题,或者提交一个新的 issue 向开发者求助。